
Data Warehousing in SQL Server – CRM and ERP Systems Integration
This project consisted of building a data warehouse in SQL Server to integrate information from two different business systems: CRM and ERP. Initially, both systems delivered data in different formats and structures, which made analysis difficult and generated inconsistencies.
To address this, I designed a solution based on the Medallion Architecture (Bronze, Silver, Gold):
-
In the Bronze layer, raw data was ingested directly from the sources.
-
In the Silver layer, cleaning and transformation processes were applied to correct inconsistencies.
-
In the Gold layer, the data model was optimized, integrity controls were applied, and it was prepared for reporting and analysis.
The result was a consolidated and user-friendly data model that enabled business teams to better analyze commercial performance and make more informed decisions.

Click to view project details on GitHub
Architecture Design
To efficiently organize and prepare the data, I designed an architecture based on the Medallion Architecture model. This structure divides the process into three layers (Bronze, Silver, and Gold), each with a clear purpose:
-
Bronze: store raw data as it comes from the sources.
-
Silver: clean, standardize, and transform the data to make it consistent.
-
Gold: optimize and model the data so it is ready for analysis and reporting.
This design made it possible to turn scattered and unstructured data into clear, reliable information ready to be used in BI, reporting, and advanced analytics.

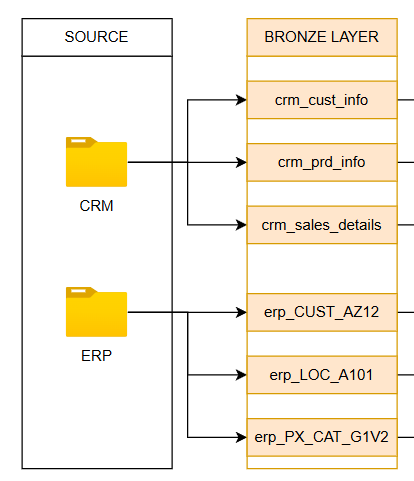
🥉 Bronze Layer – Raw Data Ingestion
In this first stage, the foundation of the data warehouse was built. The CRM and ERP data, delivered as CSV files, were loaded into SQL Server exactly as they came from the source.
To achieve this:
-
Tables and appropriate data types were defined for each file.
-
A data ingestion process was implemented using bulk insert, applying a full load strategy: tables were truncated first, and then all new information was inserted.
-
Debugging controls and error handling mechanisms were added to ensure process reliability.
-
The entire flow was documented and versioned in GitHub, ensuring traceability and ease of maintenance.
In this way, the Bronze layer consolidated all raw data in a single place, ready to move on to the cleaning and transformation process.
🥈 Silver Layer – Data Cleaning & Transformation
In this stage, the focus was on turning raw data into reliable and standardized information. The process included:
-
Exploration and verification: each table was reviewed, validating data quality and detecting inconsistencies.
-
Transformations: SQL queries were applied to clean and adjust the information (filters, window functions, conditionals, subqueries, etc.), ensuring consistency across columns and records.
-
Structure: new tables were created in the Silver schema, replicating the Bronze columns but with additional controls (e.g., DROP IF EXISTS to avoid unintended overwrites).
-
Relationships: potential primary and foreign keys (PK and FK) were identified to start shaping future data integration.
-
Validation: after each transformation, the data was verified before being inserted into the final tables.
All transformation logic and processes were documented and versioned in GitHub, ensuring traceability and project maintainability.
The result: a set of clean, standardized data ready to be integrated into a more robust business model.

🥉 Bronze Layer


🥈 Silver Layer
🥇 Gold Layer – Data Modeling & Optimization
The Gold stage focused on transforming the cleaned data into a business model ready for analysis and reporting.
The process included:
-
Definition of relationships and business objects: an Integration Model was documented showing how the tables connect, organized into three main objects: Sales, Customer, and Product.
-
Data modeling: although the tables initially formed a Snowflake schema, it was optimized into a Star Schema, which is more efficient and easier to query.
-
Advanced transformations: through SQL queries, tables were integrated by applying joins, conditional rules (to handle null values), renaming columns for clarity, and creating surrogate keys as unique identifiers.
-
Views instead of tables: the final model was built on views, ensuring flexibility to redefine business rules, preventing data duplication, and guaranteeing that reports always query up-to-date information.
-
Documentation and versioning: the complete integration flow was recorded in a Dataflow Diagram and versioned in GitHub for traceability.
The result: a consolidated, intuitive, and high-performance data model, ready to power dashboards, reports, and advanced analytics.





✅ Results and Conclusions
With this project, dispersed and poorly structured data from the CRM and ERP systems were transformed into a modern, optimized data warehouse. Thanks to the application of the Medallion Architecture, the data went through a clear process of ingestion (Bronze), cleaning and standardization (Silver), and finally business modeling (Gold).
The result was a data model that is:
-
Consolidated and ready for reporting in Business Intelligence tools.
-
Scalable and reproducible, since all processes were documented, versioned in GitHub, and built in SQL in a modular way. This makes it possible to reuse the flow with new datasets or adapt it to future business needs.
-
Robust and reliable, thanks to validation at each stage, integrity controls, and the use of views in the Gold layer that ensure information is always up to date.
From a business perspective, the organization now has a single source of truth to analyze sales, customers, and products, enabling data-driven decision-making and laying the foundation for future advanced analytics projects.
In conclusion, this project not only solved a specific data integration problem but also built a solid and flexible platform, ready to grow with the company’s needs.
Skills Demonstrated
During this project, I put into practice a set of key skills in Data Engineering and Data Analytics, including:
-
Data Architecture / Data Warehousing Design in SQL Server: implementation of a pipeline under the Medallion Architecture (Bronze, Silver, Gold).
-
ETL Processes (Extract, Transform, Load): complete data flow built from CSV files, with bulk insert loading (Extract & Load) and SQL transformations for cleaning, standardization, and modeling (Transform).
-
Data Cleaning & Transformation: application of quality rules and advanced SQL queries (window functions, subqueries, conditionals, joins, etc.).
-
Data Modeling: design of a Star Schema with dimensions, facts, and surrogate keys to optimize analysis.
-
Optimization for BI and Reporting: creation of views in the Gold layer, ensuring up-to-date information and efficient queries.
-
Documentation and Versioning: development of architecture and integration diagrams (Integration Model, Dataflow) and version control in GitHub.
-
Data Engineering Best Practices: error handling, reproducible processes, and scalable design to support future growth.